You need me to fire up a compute cluster with 1,024 cores (or more) within 15 minutes? No problem. You need it optimized for High Performance Computing (HPC) with preinstalled software for your big CFD or crash/impact simulation? Yep, can do. But before I go ahead and do that for you, let’s consider some economics.
Amazon Web Services (AWS) is currently the cloud-computing market leader with Microsoft Azure and a host of other competitors on their tails. Various cost models exist, but most commonly you pay per-core, per-hour. So if a single core costs $0.10 per hour, then ten cores cost $1 per hour. That’s simple enough, but to really take advantage of cloud computing, you must specify the proper core count for your particular problem.
Scalability
If we double the core count, we’d hope to cut solution time in half (ideal speedup). In reality there is some computing overhead associated with parallelization, so ideal speedup is not always attained. Now, if we continue piling on cores beyond the suitability of the particular problem, eventually the overhead exceeds the computational work itself and the solution slows down.
Consider the speed-up curve for a small, structural FEA job shown below. For reasons that I’ll mention below, this job scales poorly (well-below ideal).
Let’s assume the baseline solution (2 cores) took 3 hours. In terms of cloud cost, this is 2 cores x 3 hours = 6 core-hours. If we instead run on 12 cores, we complete the job 3X faster (1 hour – yay!), but we spend 12 cores x 1 hours = 12 core-hours. The cost has doubled! If the job were truly urgent, this might be worth the cost; if not, we’ve overspent. Even worse, if the analyst blindly chose to run on 24 cores, the job would still take 1 full hour and the cost would be 4X greater than the baseline solution. Ouch!
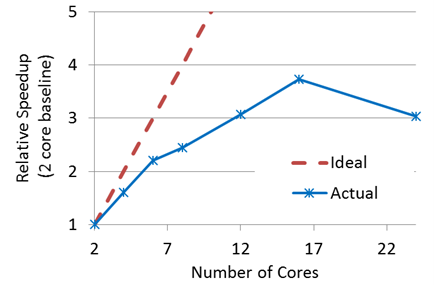
To be fair, the scenario above is a hand-picked horror story. If we know our stuff and run jobs that are well-suited for parallel computation, wonderful things can and do happen.
ANSYS CFD solvers (Fluent and CFX) are highly optimized for massively parrallel computing. The ANSYS explicit dynamics solvers (LS-DYNA and AUTODYN) are also extremely efficient on big clusters. This is where we can shine.
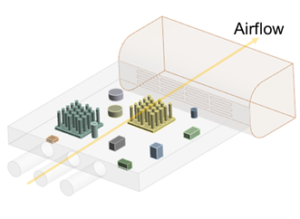
The benchmark problem below is an ANSYS Fluent simulation for a simplified electronics cooling application.
- Conjugate Heat Transfer (CHT)
- Forced convection (mass-flow inlets, pressure outlets)
- Turbulent, buoyant
- All internal solids are heat sources (wattage)
- 27 million elements (25.6 million fluid, 1.4 million solid)
- 2 million nodes
- Fine mesh at all fluid-solid interfaces
The job was run on both Amazon AWS and Microsoft Azure clusters in various modes.

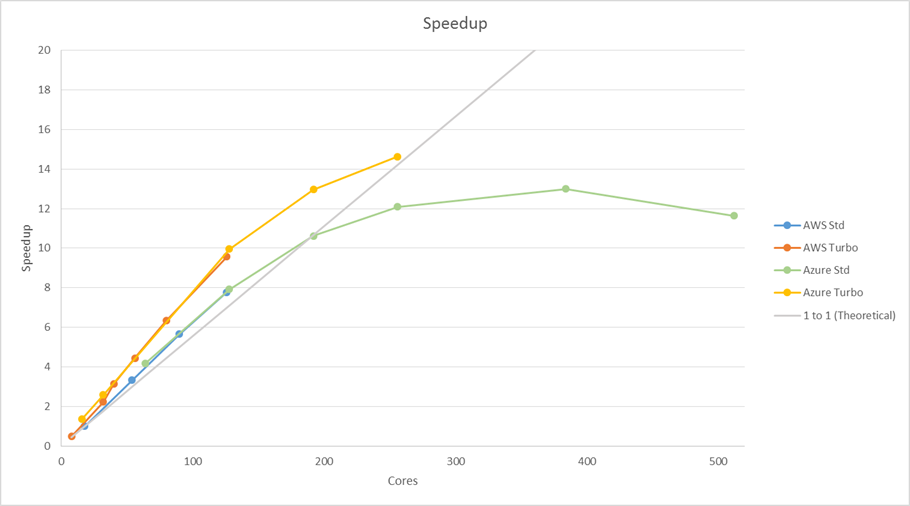
Immediate observations:
- AWS and Azure perform almost identically for similar setups.
- Speedup is super-ideal all the way up to 196 cores. The baseline condition swamps the computer, likely saturating memory and other resources. This job wants to run in parallel!
The “Sweet Spot”
Focus on the green curve above (Azure Standard Solution). We can run this job on 18 cores for 10 hours (baseline), or we can run it on 180 cores for 1 hour (10X speedup). The cost is the same! Now for the kicker… If we run on 128 cores, it would take less than 1.3 hours and would be cheaper than either of the other two scenarios. Problems like this not only get us a solution faster, they can be cheaper if we choose the core count wisely.
The image below more clearly shows the concept of the sweet spot and the diminishing returns beyond it. The vertical axis is actual wall time in this case rather than speedup.
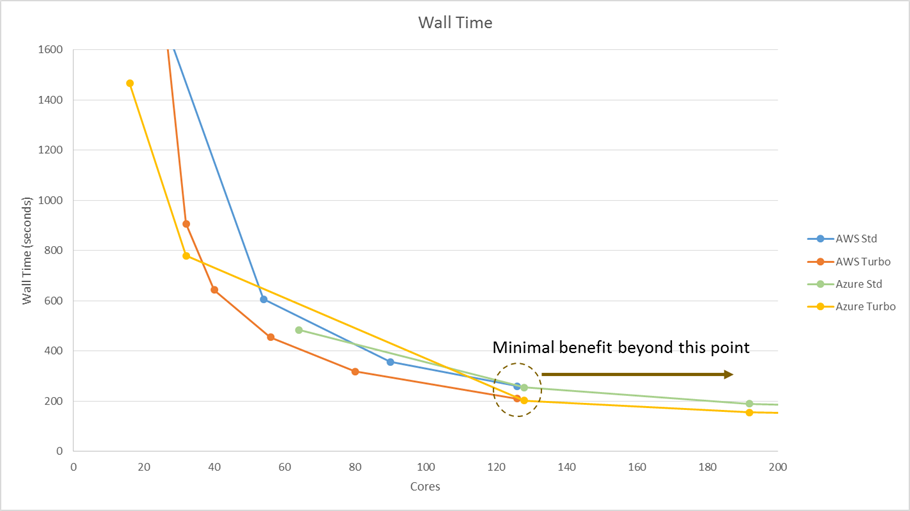
Choosing a Core Count
It’s far simpler than one might imagine to fire up a problem, run a few iterations, and measure the computing resources consumed (time). A rough version of the curves above can be constructed for a given problem in less than 30 minutes. Once completed, this information can be used for all future runs of the model and any design variants desired. It’s a simple matter of knowing what to look for and how to leverage it.
Problem Suitability
It’s pretty straightforward to conclude that a system with just a few hundred equations is not suited for thousands of computing cores. Speaking loosely, 1 million elements is no longer a “big problem” in today’s simulation environment. We commonly run these jobs on our in-house cluster here at Mallett. 10 million elements? Well now we’d consider jumping to the cloud, but it’s still not so simple.
In addition to problem size, the physics of the problem come into play. Certain equations lend themselves to parallelization better than others. Highly-coupled systems with exponential relationships (think about radiation) are difficult to solve in general and are more difficult to solve for a decomposed domain (decomposition refers to splitting the problem into chunks and distributing it to the various cores).
With some experience, one can estimate how a given problem will scale based on problem size and physics. This knowledge and experience also serves to guide us as we construct the model in the first place. A quick scalability study should be done prior to launching production runs, then you’re off to the races.
The Wall
Some problems are just too huge to solve any other way – they’re intractable on single-server hardware and simply must be run on a cluster. This is a rare case. Most often there is a choice to make. The analyst must use knowledge and experience while constructing the model. Plan ahead whether a given job is destined for the cluster or not, then model accordingly.
Bottom Line
I dare say that scalability for massively parallel computing has grown beyond adolescence and is nearing maturity (at least for traditional CPU architectures). The speeds attainable on massive computing clusters is mind-numbing. Running solutions on these systems feels like hopping off an old mule and into a Formula One race car. The thing is, there are certain situations where that old mule will do the job just fine for a tiny fraction of the cost, and there’s a wide spectrum of situations in between.
We maintain a pretty darn good cluster in-house at Mallett, but there are plenty of times when we jump to the cloud for truly massive processing. We’ve got lots of experience with both AWS and Azure, and we know how to tune and optimize them for performance. These are exciting times, and we’re glad to be piloting this exhilarating ride.
Mallett Technology, Inc has been providing mechanical engineering solutions since 1974.
Jason Mareno is a Licensed Professional Engineer with 20+ years of experience. Having a background in product development as well as CAE, he has led product development teams from concept through commercialization for products with volumes of 20 million units and revenues in excess of $4 billion. He heads up Mallett’s consulting group and is responsible for business development, staffing, and technical excellence/quality.